
Olmo 3 é um LLM totalmente aberto
Olmo 3 é um LLM totalmente aberto
22 de novembro de 2025
Olmo é a série LLM da Ai2 – o Instituto Allen de IA. Ao contrário da maioria dos modelos de peso aberto, estes são notáveis por incluir dados completos de treinamento, processo de treinamento e pontos de verificação junto com essas versões.
O novo Olmo 3 afirma ser “o melhor modelo de pensamento totalmente aberto em escala 32B” e tem um forte foco na interpretabilidade:
No seu centro está Olmo 3-Pense (32B)o melhor modelo de pensamento totalmente aberto em escala 32B que, pela primeira vez, permite inspecionar traços de raciocínio intermediários e rastrear esses comportamentos até os dados e as decisões de treinamento que os produziram.
Eles lançaram quatro modelos 7B – Olmo 3-Base, Olmo 3-Instruct, Olmo 3-Think e Olmo 3-RL Zero, além de variantes 32B dos modelos 3-Think e 3-Base.
Ter acesso total aos dados de treinamento é muito útil. Veja como eles descrevem isso:
Olmo 3 é pré-treinado em Recheado 3um novo corpus de aproximadamente 9,3 trilhões de tokens extraído de páginas da web, PDFs científicos processados com olmOCR, bases de código, problemas e soluções matemáticas e texto enciclopédico. A partir deste pool, construímos Dolma 3 Misturauma mistura de pré-treinamento de 5,9 trilhões de tokens (~6T) com uma proporção maior de codificação e dados matemáticos do que versões anteriores do Dolma, além de descontaminação muito mais forte por meio de desduplicação extensiva, filtragem de qualidade e controle cuidadoso sobre a mistura de dados. Seguimos os padrões estabelecidos da web na coleta de dados de treinamento e não os coletamos de sites que explicitamente os proíbam, incluindo conteúdo com acesso pago.
Eles também destacam que estão treinando com menos tokens do que seus concorrentes:
(…) é o modelo de pensamento totalmente aberto mais forte que conhecemos, diminuindo a lacuna para os melhores modelos de peso aberto de escala semelhante – como Qwen 3 32B – enquanto treina em cerca de 6x menos tokens.
Se você continua tendo esperança de um modelo treinado inteiramente em dados licenciados, este infelizmente não será adequado – muitos desses dados ainda vêm de um rastreamento da web.
Experimentei o modelo 32B Think e o modelo 7B Instruct usando LM Studio. O modelo 7B tem um download de 4,16 GB, o 32B tem 18,14 GB.
O modelo 32B é absolutamente pensado demais! Pedi para “Gerar um SVG de um pelicano andando de bicicleta” e ele pensou em 14 minutos e 43 segundosgerando um total de 8.437 tokens, a maioria dos quais era esse traço de pensamento épico.
Normalmente não cito o SVG completo nesses artigos, mas neste caso é curto o suficiente para que valha a pena compartilhar. Os comentários do SVG dão uma ótima impressão do que ele estava tentando fazer – tem Bicicleta, Quadro de Bicicleta, Pelicano, Asas Esquerda e Direita e até “Pés nos pedais”.
<svg width="200" height="200" viewBox="0 0 100 100">
<circle cx="30" cy="60" r="15" stroke="black" fill="none"/>
<circle cx="70" cy="60" r="15" stroke="black" fill="none"/>
<rect x="35" y="25" width="30" height="10" fill="saddlebrown"/>
<line x1="35" y1="40" x2="30" y2="60" stroke="black" stroke-width="3"/>
<line x1="65" y1="40" x2="70" y2="60" stroke="black" stroke-width="3"/>
<ellipse cx="55" cy="65" rx="20" ry="15" fill="white"/>
<polygon points="52 50,57 35,62 50" fill="black"/>
<circle cx="55" cy="45" r="2" fill="white"/>
<circle cx="60" cy="45" r="2" fill="white"/>
<polygon points="45 60,50 70,55 60" fill="lightgrey"/>
<polygon points="65 60,70 70,55 60" fill="lightgrey"/>
<polygon points="25 75,30 85,35 75" fill="black"/>
<polygon points="75 75,70 85,65 75" fill="black"/>
svg>
Renderizado fica assim:
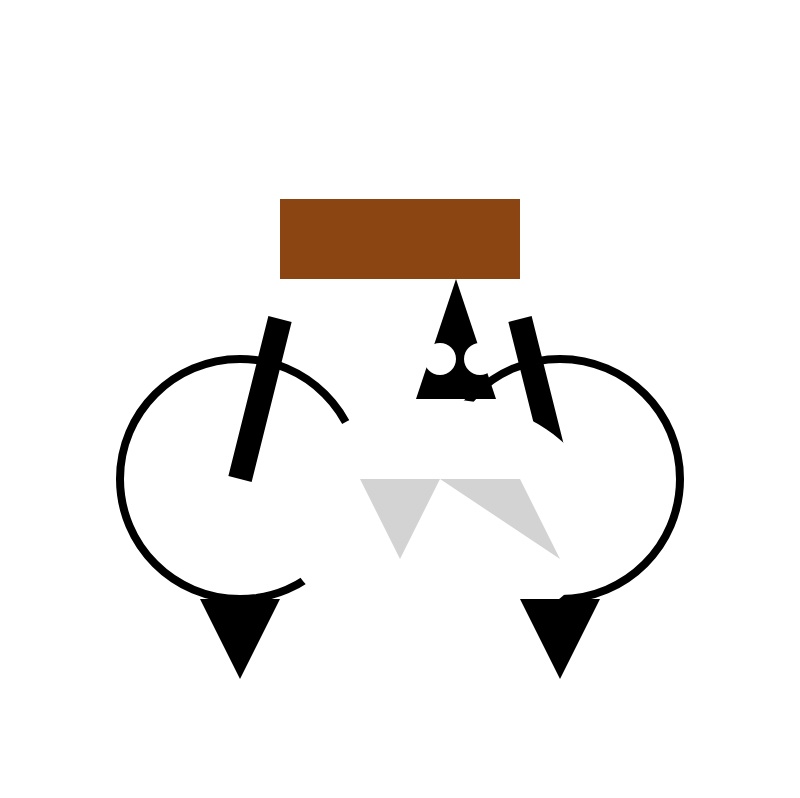
Testei o OLMo 2 32B 4bit em março e consegui algo que, embora agradavelmente abstrato, não chegou nem perto de se parecer com um pelicano ou uma bicicleta:
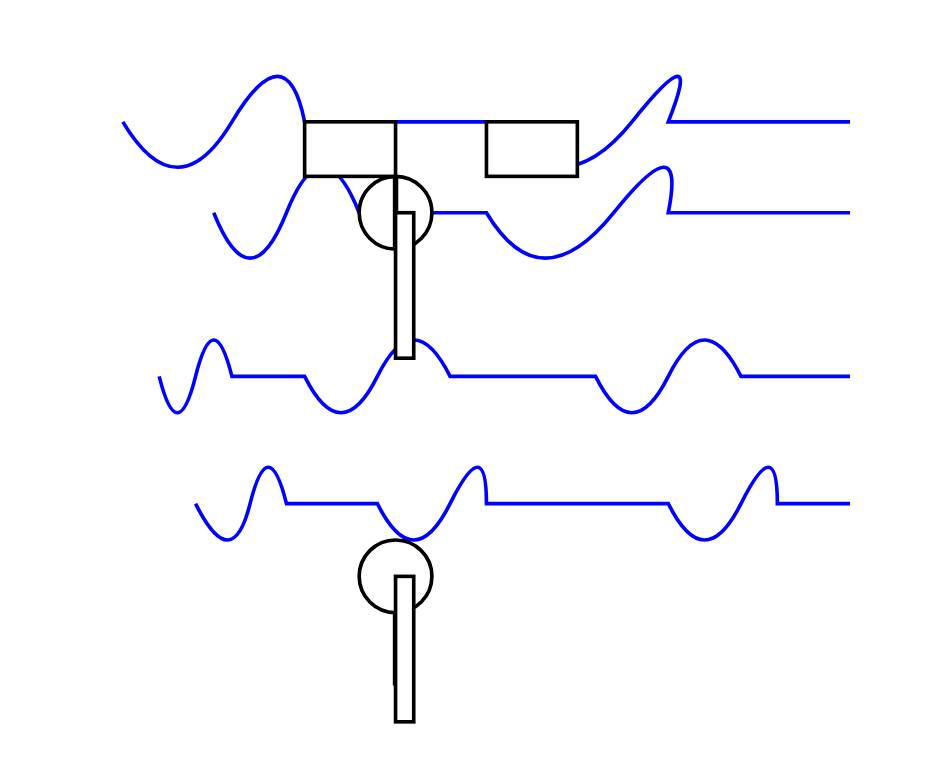
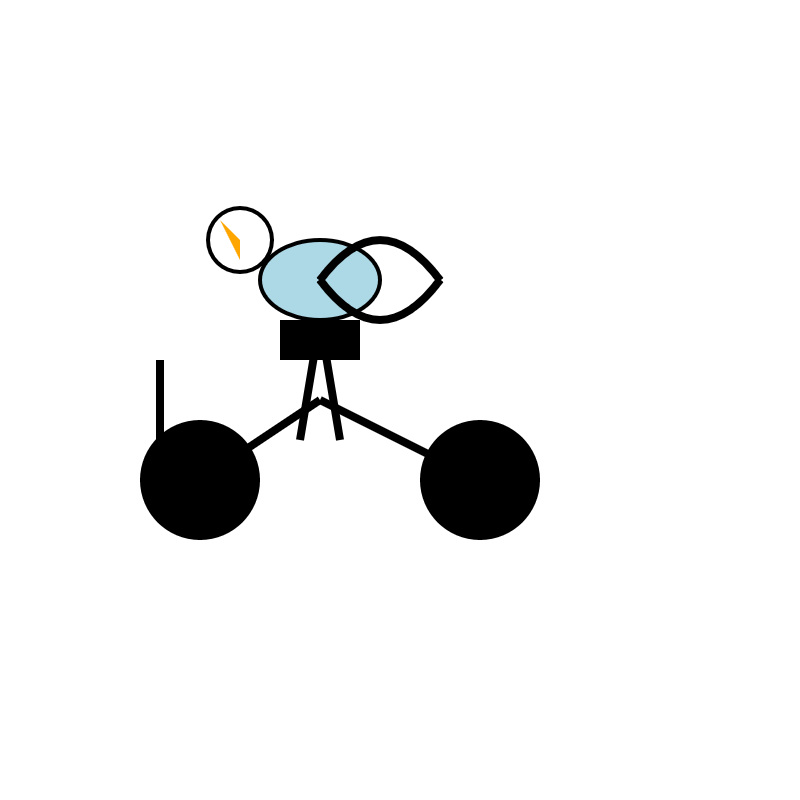
Para ser justo, os modelos 32B geralmente não se dão bem com isso. Aqui está a tentativa do Qwen 3 32B (eu executei isso agora usando o OpenRouter):
OlmoTrace
Eu estava particularmente interessado em testar a capacidade de “inspecionar traços de raciocínio intermediários”. Veja como isso é descrito posteriormente no anúncio:
Um objetivo central do Olmo 3 não é apenas abrir o fluxo do modelo, mas para fazê-lo acionável para pessoas que desejam compreender e melhorar o comportamento do modelo. Olmo 3 integra-se com OlmoTracenossa ferramenta para rastrear resultados de modelos até dados de treinamento em tempo real.
Por exemplo, no Ai2 Playground, você pode pedir ao Olmo 3-Think (32B) para responder a uma pergunta de conhecimento geral e, em seguida, usar o OlmoTrace para inspecionar onde e como o modelo pode ter aprendido a gerar partes de sua resposta. Isso fecha a lacuna entre os dados de treinamento e o comportamento do modelo: você pode ver não apenas o que o modelo está fazendo, mas por que — e ajustar os dados ou as decisões de treinamento de acordo.
Você pode acessar o OlmoTrace via playground.allenai.org, primeiro executando um prompt e depois clicando no botão “Mostrar OlmoTrace” abaixo da saída.
Eu tentei isso em “Gerar uma biografia de conferência para Simon Willison” (um prompt do ego que uso para ver o quanto os modelos aprenderam sobre mim a partir de seus dados de treinamento) e obtive um resultado parecido com este:

Ele acha que fui co-fundador: aqui e trabalho na Anthropic, ambos incorretos – mas isso não é incomum com LLMs, frequentemente os vejo sugerir que sou o CTO do GitHub e outras imprecisões semelhantes.
Achei o painel OlmoTrace à direita decepcionante. Nenhum dos documentos de treinamento destacados tinha nada a ver comigo – parece estar procurando correspondências de frases (alimentado pelo infinigrama de Ai2), mas os documentos que encontrou não tinham nada a ver comigo.
Os dados de treinamento abertos podem resolver preocupações de backdoors?
Ai2 afirma que Olmo 3 é “o melhor modelo de pensamento totalmente aberto em escala 32B”, o que eu acho que se mantém desde que você defina “totalmente aberto” como incluindo dados de treinamento abertos. Porém, não há muita competição nesse espaço – Ai2 se compara ao Marin de Stanford e ao Apertus da AI suíça, nenhum dos quais eu já tinha ouvido falar antes.
Uma grande desvantagem de outros modelos de peso aberto é que é impossível auditar seus dados de treinamento. A Anthropic publicou um artigo no mês passado mostrando que um pequeno número de amostras pode envenenar LLMs de qualquer tamanho – podem ser necessários apenas “250 documentos envenenados” para adicionar um backdoor a um modelo grande que desencadeia comportamento indesejado com base em um prompt curto e cuidadosamente elaborado.
Isso torna os dados de treinamento totalmente abertos um negócio ainda maior. Espero que vejamos mais concorrência neste espaço, incluindo mais modelos da série Olmo. As melhorias do Olmo 1 (em fevereiro de 2024) e do Olmo 2 (em março de 2025) foram significativas. Espero que essa tendência continue!





