
Gêmeos aprimorados 2.5 flash e flash-lite
Gêmeos aprimorados 2.5 flash e flash-lite (via) dois novos modelos de visualização do Google – atualizações para suas famílias rápidas e baratas do flash e Flash Lite:
A versão mais recente do Gemini 2.5 Flash-Lite foi treinada e construída com base em três temas-chave:
- Melhor instrução a seguir: O modelo é significativamente melhor para seguir as instruções complexas e os avisos do sistema.
- Verbosidade reduzida: Agora produz respostas mais concisas, um fator-chave na redução de custos de token e latência para aplicativos de alto rendimento (consulte os gráficos acima).
- Recursos multimodais e de tradução mais fortes: Esta atualização apresenta uma transcrição de áudio mais precisa, melhor compreensão da imagem e melhor qualidade de tradução.
(…)
Este mais recente modelo Flash 2.5 vem com melhorias em duas áreas -chave que ouvimos feedback consistente:
- Melhor uso da ferramenta agêntica: Melhoramos como o modelo usa ferramentas, levando a um melhor desempenho em aplicativos mais complexos, agênticos e de várias etapas. Este modelo mostra melhorias notáveis nos principais benchmarks agênticos, incluindo um ganho de 5% no SWE-banch verificado, em comparação com nossa última liberação (48,9% → 54%).
- Mais eficiente: Com o pensamento, o modelo agora é significativamente mais econômico-atendendo aos resultados de maior qualidade enquanto usam menos tokens, reduzindo a latência e o custo (consulte os gráficos acima).
Eles também adicionaram dois novos IDs de modelo de conveniência: gemini-flash-latest e gemini-flash-lite-latestque sempre resolverá o modelo mais recente nessa família.
Lançei o LLM-Geminini 0.26 Adicionando suporte para os novos modelos e novos aliases. Eu também usei o response.set_resolved_model() Método adicionado no LLM 0,27 para garantir que o ID do modelo correto seja registrado para aqueles -latest usos.
llm install -U llm-gemini
Ambos os modelos suportam tokens de raciocínio opcionais. Eu os desenhei atrair Pelicanos andando de bicicleta no modo de pensamento e sem pensamento, usando comandos que pareciam assim:
llm -m gemini-2.5-flash-preview-09-2025 -o thinking_budget 4000 "Generate an SVG of a pelican riding a bicycle"
Em seguida, tenho cada modelo para descrever a imagem que ele desenhara usando comandos como este:
llm -a https://static.simonwillison.net/static/2025/gemini-2.5-flash-preview-09-2025-thinking.png -m gemini-2.5-flash-preview-09-2025 -o thinking_budget 2000 'Detailed single line alt text for this image'
Gemini-2.5-Flash-Preview-09-2025-pensando

Um gráfico de figura minimalista mostra uma pessoa com um corpo oval branco e uma cabeça de ponto de bicicleta de bicicleta cinza, carregando uma caixa retangular amarela grande e brilhante apoiada no alto das costas.
Gemini-2.5-Flash-Preview-09-2025
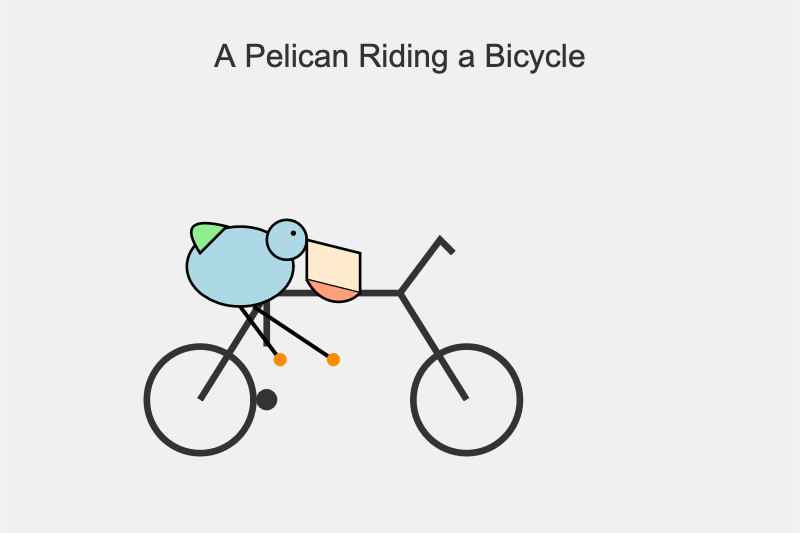
Um simples desenho de desenho animado de um pelicano andando de bicicleta, com o texto “um pelicano andando de bicicleta” acima dela.
GEMINI-2.5-FLASH-LITE-PREVIEW-09-2025-PINCULING

Uma ilustração peculiar e simplificada do desenho animado de um pássaro branco com um corpo redondo, olho preto e bico amarelo brilhante, sentado montado em um veículo cinza escuro e duas rodas com seus pés cor de pêssego pendurados abaixo.
GEMINI-2.5-FLASH-LITE-PREVIED-09-2025

Uma ilustração minimalista de perfil lateral de uma garota amarela estilizada ou um caractere de pássaro montando um veículo de roda escura em uma faixa verde contra um fundo branco.
Análise artificial postada uma revisão detalhadaincluindo estas notas interessantes sobre a eficiência e a velocidade do raciocínio:
- No modo de raciocínio, o Gemini 2.5 Flash e o Flash-Lite visualizam 09-2025 são mais eficientes em termos de token, usando menos tokens de saída do que seus antecessores para executar o índice de inteligência de análise artificial. A visualização de flash-lite Gemini 2.5 09-2025 usa 50% menos tokens de saída do que seu antecessor, enquanto a Gemini 2.5 Flash Visualize 09-2025 usa 24% menos tokens de saída.
- O Google Gemini 2.5 Flash-Lite Preview 09-2025 (raciocínio) é ~ 40% mais rápido que o lançamento anterior em julho, fornecendo ~ 887 tokens/s no estúdio do Google AI em nosso benchmarking de desempenho de endpoint da API. Isso faz do novo Gemini 2.5 Flash-Lite o modelo proprietário mais rápido que comparamos no site de análise artificial

” com Taase e Harley G – JamSphere")


 – “Song for a Diva” –")
