
Experimentando o QWEN3 Coder Flash usando o LM Studio e o Open Webui e o LLM
Experimentando o QWEN3 Coder Flash usando o LM Studio e o Open Webui e o LLM
31 de julho de 2025
A QWEN acaba de lançar seu sexto modelo (!) De julho, chamado QWEN3-CODER-30B-A3B-INSTRUCT-listado como QWEN3-CODER-FLASH em sua interface Chat.qwen.ai.
São 30,5b parâmetros totais com 3,3b ativos a qualquer momento. Isso significa que ele se encaixará em um Mac de 64 GB – e até um Mac de 32 GB se você quantizá -lo – e pode ser executado realmente rápido graças a esse conjunto menor de parâmetros ativos.
É um modelo sem pensamento que é especialmente treinado para tarefas de codificação.
Esta é uma combinação emocionante de propriedades: otimizada para o desempenho e velocidade de codificação e pequena o suficiente para ser executado em um laptop de desenvolvedor de nível intermediário.
Experimentando com o LM Studio e o Open Webui
Gosto de executar modelos como esse usando a estrutura MLX da Apple. Eu corri o Air GLM-4.5 outro dia usando a biblioteca MLX-LM Python diretamente, mas desta vez decidi experimentar a combinação do LM Studio e do Open Webui.
(O LM Studio tem uma interface decente incorporada, mas eu gosto do Open Webui um um pouco mais.)
Instalei o modelo clicando no botão “Use Model in LM Studio” na página QWEN/QWEN3-CODER-30B do LM Studio. Isso me deu várias opções:
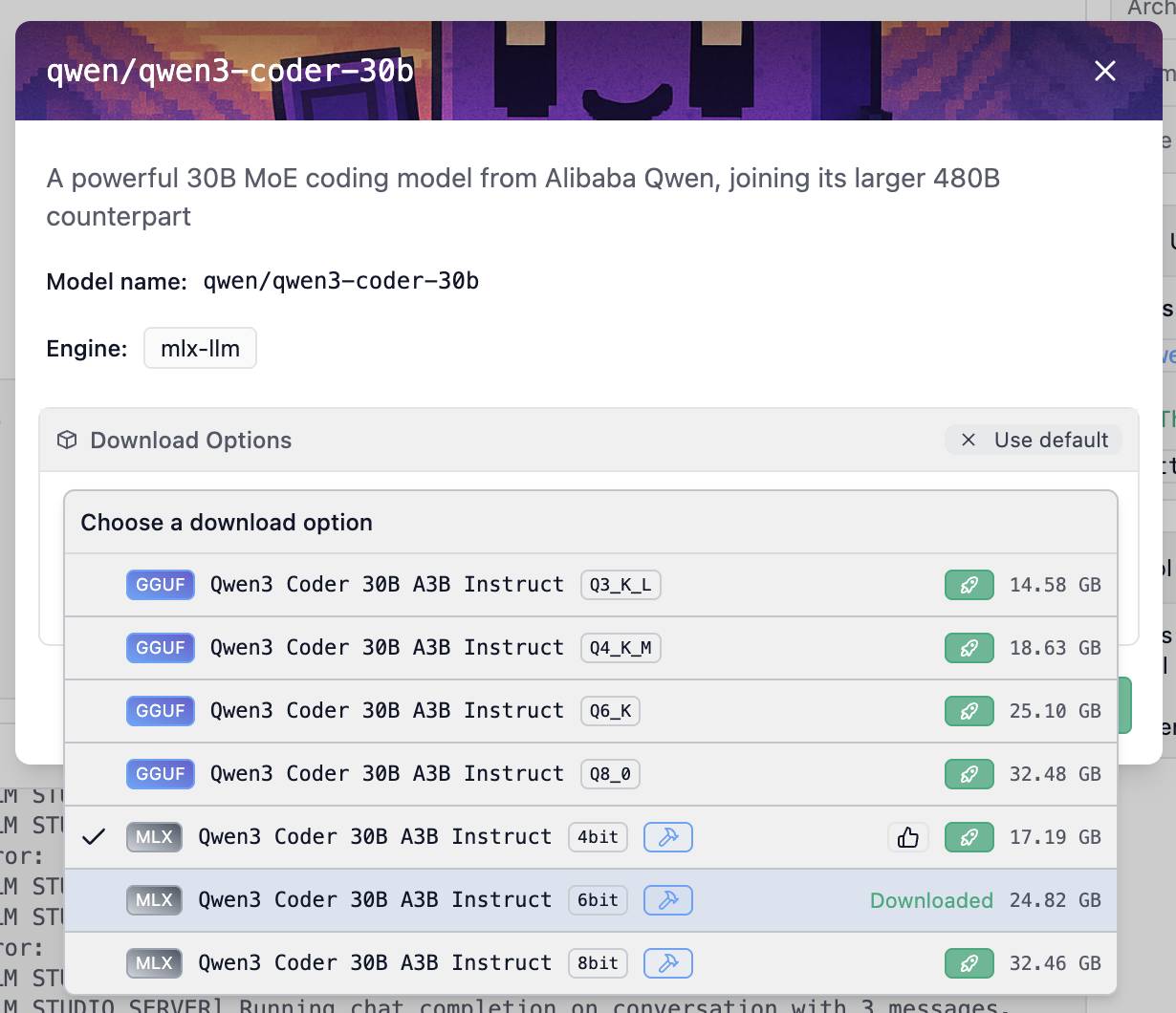
Eu escolhi o modelo MLX de 6 bits, que é um download de 24,82 GB. Outras opções incluem 4bit (17,19 GB) e 8 bits (32,46 GB). Os tamanhos de download são aproximadamente os mesmos que a quantidade de RAM necessária para executar o modelo – escolhendo que 24 GB deixa 40 GB livre na minha máquina de 64 GB para outras aplicações.
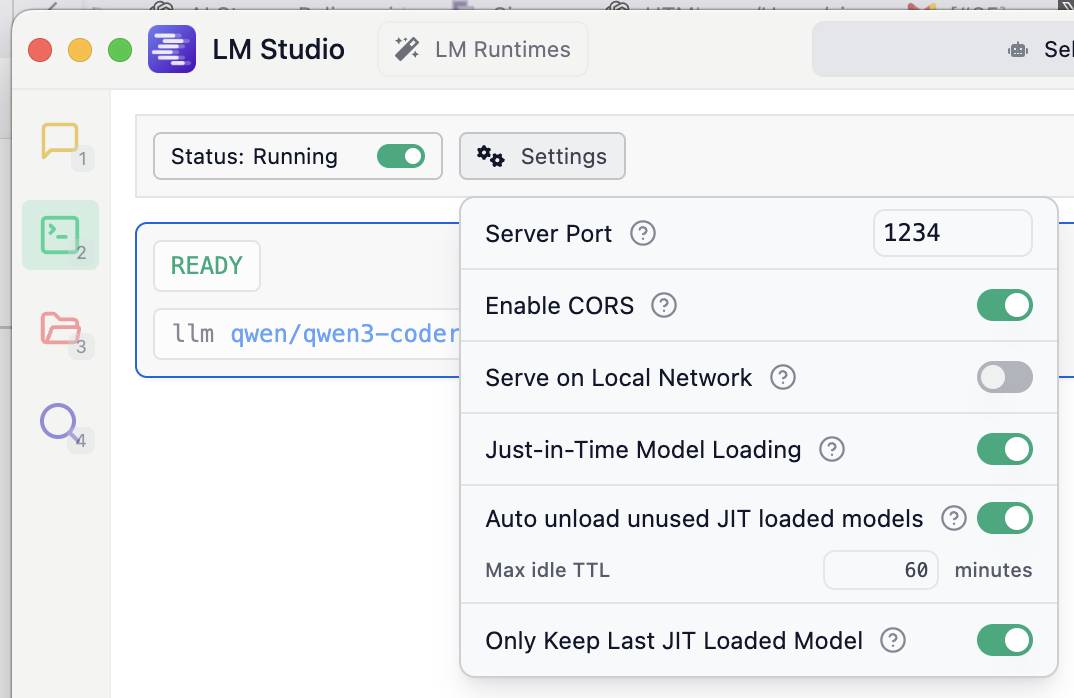
Então eu abri as configurações do desenvolvedor no LM Studio (o ícone da pasta verde) e liguei “Ativar cors” para que eu pudesse acessá -lo a partir de uma instância aberta WebUI aberta.
Agora eu mudei para abrir o webui. Eu instalei e o executei usando UV assim:
uvx --python 3.11 open-webui serve
Então navegou para http://localhost:8080/ Para acessar a interface. Abri as configurações deles e configurei uma nova “conexão” ao LM Studio:
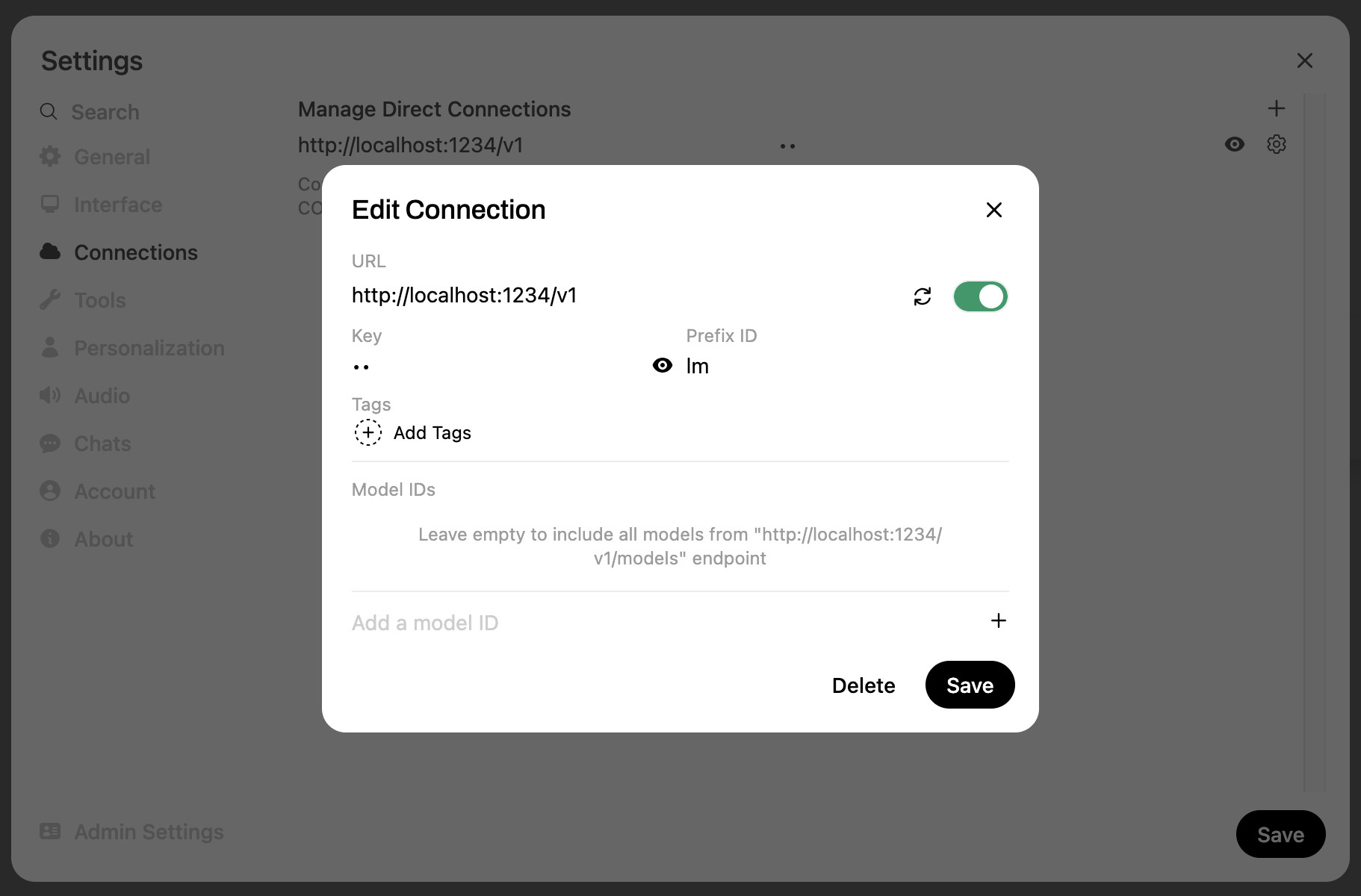
Que precisa de um URL base de http://localhost:1234/v1 E uma chave de tudo o que você quiser. Eu também defino o prefixo opcional para lm Apenas caso minha instalação do Ollama – que a webui aberta detecte automaticamente – vá com qualquer nome de modelo duplicado.
Depois de fazer tudo isso, eu poderia selecionar qualquer um dos meus modelos de estúdio LM na interface Open Webui e começar a executar os prompts.
Um recurso interessante do Open Webui é que ele inclui um painel de visualização automática, que inicia blocos de código cercados que incluem SVG ou HTML:

Aqui está a transcrição exportada para “gerar um SVG de um pelicano andando de bicicleta”. Ele correu em quase 60 tokens por segundo!
Implementando invasores de espaço
Eu tentei meu outro prompt de benchmark simples recente também:
Write an HTML and JavaScript page implementing space invaders
Eu gosto deste, porque é um aviso muito curto que atua como abreviação de um conjunto bastante complexo de recursos. Provavelmente, há muito material nos dados de treinamento para ajudar o modelo a atingir esse objetivo, mas ainda é interessante ver se eles conseguem cuspir algo que funciona pela primeira vez.
A primeira versão que me deu trabalhou fora da caixa, mas foi um pouco difícil demais – as balas inimigas se movem tão rápido que é quase impossível evitá -las:
Você pode tentar isso aqui.
Eu tentei um prompt de acompanhamento de “tornar as balas inimigas um pouco mais lentamente”. Um sistema como artefatos Claude ou Claude Code implementa a ferramenta que exige modificar arquivos no local, mas o sistema Webui aberto que eu estava usando não tinha um equivalente padrão, o que significa que o modelo teve que gerar o arquivo completo pela segunda vez.
Fiz isso e desacelerou as balas, mas também fez várias outras mudanças, mostradas nesse diferencial. Não estou muito surpreso com isso – arcar com um modelo local de 25 GB para gerar um arquivo longo com apenas uma alteração é um alongamento.
Aqui está a transcrição exportada para esses dois avisos.
Executando modelos de estúdio LM com MLX-LM
LM Studio armazena seus modelos no ~/.cache/lm-studio/models diretório. Isso significa que você pode usar a biblioteca MLX-LM Python para executar instruções através do mesmo modelo como este:
uv run --isolated --with mlx-lm mlx_lm.generate \
--model ~/.cache/lm-studio/models/lmstudio-community/Qwen3-Coder-30B-A3B-Instruct-MLX-6bit \
--prompt "Write an HTML and JavaScript page implementing space invaders" \
-m 8192 --top-k 20 --top-p 0.8 --temp 0.7
Esteja ciente de que isso carregará uma cópia duplicada do modelo na memória, para que você queira sair do LM Studio antes de executar este comando!
Acessando o modelo através da minha ferramenta LLM
Meu projeto LLM fornece uma ferramenta de linha de comando e biblioteca Python para acessar grandes modelos de idiomas.
Como o LM Studio oferece uma API compatível com o OpenAI, você pode configurar o LLM para acessar modelos por meio dessa API criando ou editando o ~/Library/Application\ Support/io.datasette.llm/extra-openai-models.yaml arquivo:
zed ~/Library/Application\ Support/io.datasette.llm/extra-openai-models.yaml
Eu adicionei a seguinte configuração YAML:
- model_id: qwen3-coder-30b
model_name: qwen/qwen3-coder-30b
api_base: http://localhost:1234/v1
supports_tools: true
Desde que o LM Studio esteja em execução, posso executar instruções do meu terminal assim:
llm -m qwen3-coder-30b 'A joke about a pelican and a cheesecake'
Por que o pelicano se recusou a comer o cheesecake?
Porque tinha um bico para a sobremesa! 🥧🦜
(Ou se você preferir: porque tinha medo de conseguir bico-Sticre de toda aquela bondade cremosa!)
(25 GB claramente não é espaço suficiente para um senso de humor funcional.)
Mais interessante, porém, podemos começar a exercitar o suporte do modelo QWEN para chamadas de ferramentas:
llm -m qwen3-coder-30b \
-T llm_version -T llm_time --td \
'tell the time then show the version'
Aqui estamos permitindo que as duas ferramentas padrão da LLM – uma por contar o tempo e outra para ver a versão do LLM que está atualmente instalada. O --td bandeira significa --tools-debug.
A saída se parece com esta, a saída de depuração incluiu:
Tool call: llm_time({})
{
"utc_time": "2025-07-31 19:20:29 UTC",
"utc_time_iso": "2025-07-31T19:20:29.498635+00:00",
"local_timezone": "PDT",
"local_time": "2025-07-31 12:20:29",
"timezone_offset": "UTC-7:00",
"is_dst": true
}
Tool call: llm_version({})
0.26
The current time is:
- Local Time (PDT): 2025-07-31 12:20:29
- UTC Time: 2025-07-31 19:20:29
The installed version of the LLM is 0.26.
Muito bom! Ele conseguiu duas chamadas de ferramentas de um único prompt.
Infelizmente, eu não conseguia fazer isso funcionar com alguns dos meus plugins mais complexos, como o LLM-Tools-Sqlite. Estou tentando descobrir se esse é um bug no modelo, a camada de estúdio LM ou meu próprio código para executar prompts de ferramentas contra pontos de extremidade compatíveis com o OpenAI.
O mês de Qwen
Julho foi absolutamente o mês de Qwen. Os modelos que eles lançaram este mês são excelentes, empacotando alguns recursos extremamente úteis, mesmo em modelos que posso executar em 25 GB de RAM ou menos no meu próprio laptop.
Se você está procurando um modelo de codificação competente, pode executar localmente QWEN3-CODER-30B-A3B é uma escolha muito sólida.





