
Como automatizo meu boletim informativo Substack com conteúdo do meu blog
Como automatizo meu boletim informativo Substack com conteúdo do meu blog
19 de novembro de 2025
Enviei meu boletim informativo semanal Substack esta manhã e aproveitei a oportunidade para gravar um vídeo no YouTube demonstrando meu processo e descrevendo os diferentes componentes que o fazem funcionar. Há um muito de fita adesiva digital envolvida, levando o conteúdo de Django+Heroku+PostgreSQL para GitHub Actions para SQLite+Datasette+Fly.io para JavaScript+Observable e finalmente para Substack.
O processo principal é o mesmo que descrevi em 2023. Tenho um bloco de notas Observable chamado blog-to-newsletter que busca conteúdo do banco de dados do meu blog, filtra tudo o que já esteve no boletim informativo antes, formata o que resta como HTML e oferece um grande botão “Copiar boletim informativo em rich text para a área de transferência”.
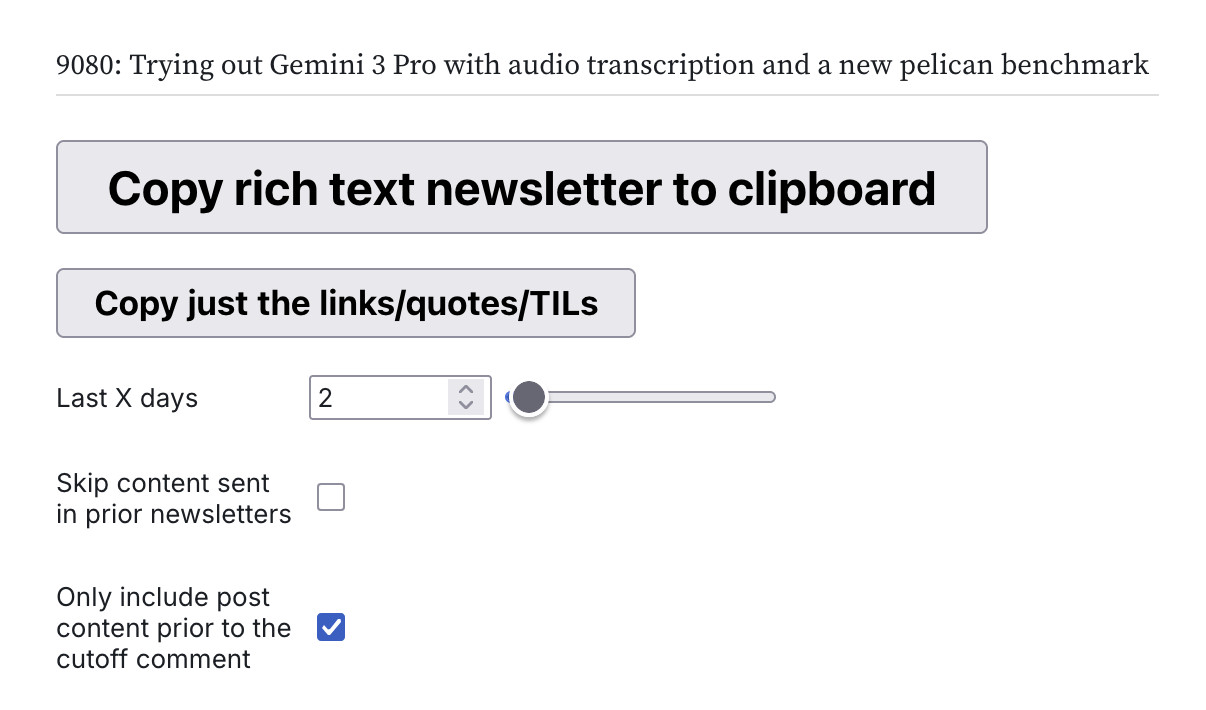
Clico nesse botão, colo o resultado no editor Substack, ajusto algumas coisas e clico em enviar. Todo o processo geralmente leva apenas alguns minutos.
Eu faço pequenas edições:
- Defino o título e o subtítulo da newsletter. Geralmente é uma cópia direta do título da postagem do blog em destaque.
- Substack transforma URLs do YouTube em incorporações, o que muitas vezes não é o que eu quero, especialmente se eu tiver um URL do YouTube dentro de um exemplo de código.
- Blocos de texto pré-formatado geralmente têm uma linha extra em branco no final, que eu removo.
- Ocasionalmente, faço uma edição de conteúdo – removendo um conteúdo que não cabe no boletim informativo ou fixando uma referência de tempo como “ontem” que não faz mais sentido.
- Eu escolho a imagem em destaque para o boletim informativo e adiciono algumas tags.
Esse é todo o processo!
O caderno observável
A célula mais importante do notebook Observable é esta:
raw_content = {
return await (
await fetch(
`https://datasette.simonwillison.net/simonwillisonblog.json?sql=${encodeURIComponent(
sql
)}&_shape=array&numdays=${numDays}`
)
).json();
}
Isso usa o JavaScript fetch() função para extrair dados da instância Datasette do meu blog, usando uma consulta SQL muito complexa que é composta em outro lugar do notebook.
Aqui está um link para ver e executar essa consulta diretamente no Datasette. São 143 linhas de SQL complicado que monta a maior parte do HTML do boletim informativo usando concatenação de strings SQLite! Um trecho ilustrativo:
with content as (
select
id,
'entry' as type,
title,
created,
slug,
''
|| 'https://simonwillison.net/' || strftime('%Y/', created)
|| substr('JanFebMarAprMayJunJulAugSepOctNovDec', (strftime('%m', created) - 1) * 3 + 1, 3)
|| '/' || cast(strftime('%d', created) as integer) || '/' || slug || '/' || '">'
|| title || ' - ' || date(created) || '' || body
as html,
'null' as json,
'' as external_url
from blog_entry
union all
# ...
Os URLs do meu blog se parecem com /2025/Nov/18/gemini-3/—este SQL constrói aquela abreviatura de três letras do mês a partir do número do mês usando uma operação de substring.
Este é um terrível maneira de montar HTML, mas continuei porque me diverte.
O resto do bloco de notas Observable pega esses dados, filtra qualquer coisa que esteja vinculada ao conteúdo mencionado nos boletins informativos anteriores e os compõe em um bloco de HTML que pode ser copiado usando aquele botão grande.
Aqui está a receita usada para transformar HTML em conteúdo rich text em uma área de transferência adequada para Substack. Não me lembro como descobri isso, mas é muito eficaz:
Object.assign(
html`<button style="https://simonwillison.net/2025/Nov/19/how-i-automate-my-substack-newsletter/font-size: 1.4em; padding: 0.3em 1em; font-weight: bold;"https://simonwillison.net/2025/Nov/19/how-i-automate-my-substack-newsletter/>Copy rich text newsletter to clipboard`,
{
onclick: () => {
const htmlContent = newsletterHTML;
// Create a temporary element to hold the HTML content
const tempElement = document.createElement("div");
tempElement.innerHTML = htmlContent;
document.body.appendChild(tempElement);
// Select the HTML content
const range = document.createRange();
range.selectNode(tempElement);
// Copy the selected HTML content to the clipboard
const selection = window.getSelection();
selection.removeAllRanges();
selection.addRange(range);
document.execCommand("copy");
selection.removeAllRanges();
document.body.removeChild(tempElement);
}
}
)
Do Django+Postgresql ao Datasette+SQLite
Meu blog em si é um aplicativo Django hospedado no Heroku, com dados armazenados no Heroku PostgreSQL. Aqui está o código fonte desse aplicativo Django. Eu uso o administrador do Django como meu CMS.
O Datasette fornece uma API JSON sobre um banco de dados SQLite… o que significa que algo precisa converter esse banco de dados PostgreSQL em um banco de dados SQLite que o Datasette possa usar.
Meu sistema para fazer isso está no repositório GitHub simonw/simonwillisonblog-backup. Ele usa GitHub Actions em uma programação executada a cada duas horas, buscando os dados mais recentes do PostgreSQL e convertendo-os em SQLite.
Minha ferramenta db-to-sqlite é responsável por essa conversão. Eu chamo assim:
db-to-sqlite \
$(heroku config:get DATABASE_URL -a simonwillisonblog | sed s/postgres:/postgresql+psycopg2:/) \
simonwillisonblog.db \
--table auth_permission \
--table auth_user \
--table blog_blogmark \
--table blog_blogmark_tags \
--table blog_entry \
--table blog_entry_tags \
--table blog_quotation \
--table blog_quotation_tags \
--table blog_note \
--table blog_note_tags \
--table blog_tag \
--table blog_previoustagname \
--table blog_series \
--table django_content_type \
--table redirects_redirect
Que heroku config:get DATABASE_URL O comando usa credenciais do Heroku em uma variável de ambiente para buscar a URL de conexão do banco de dados PostgreSQL do meu blog (e corrige uma pequena diferença no esquema de URL).
db-to-sqlite pode então exportar esses dados e gravá-los em um arquivo de banco de dados SQLite chamado simonwillisonblog.db.
O --table as opções especificam as tabelas que devem ser incluídas na exportação.
O repositório faz mais do que apenas essa conversão: ele também exporta os dados resultantes para arquivos JSON que residem no repositório, o que me fornece um histórico de commits das alterações que faço em meu conteúdo. Esta é uma maneira barata de obter um histórico de revisão do conteúdo do meu blog sem ter que mexer no rastreamento detalhado do histórico dentro do próprio aplicativo Django.
No final do meu fluxo de trabalho do GitHub Actions está este código que publica o banco de dados resultante no Datasette em execução no Fly.io usando o plug-in datasette publicar fly:
datasette publish fly simonwillisonblog.db \
-m metadata.yml \
--app simonwillisonblog-backup \
--branch 1.0a2 \
--extra-options "--setting sql_time_limit_ms 15000 --setting truncate_cells_html 10000 --setting allow_facet off" \
--install datasette-block-robots \
# ... more plugins
Como você pode ver, há muitas peças móveis! Surpreendentemente, tudo basicamente funciona – raramente preciso intervir no processo e o custo desses diferentes componentes é agradavelmente baixo.





