
Codificação agêntica no mundo
QWEN3-CODER: Codificação Agentic no mundo (Via) Acontece que, enquanto eu estava digitando minhas anotações sobre QWEN3-235B-A22B-Instruct-2507, a equipe QWEN estava desencadeando algo muito maior:
Hoje, estamos anunciando o QWEN3-Coder, nosso modelo de código mais agêntico até o momento. Qwen3-Coder is available in multiple sizes, but we’re excited to introduce its most powerful variant first: Qwen3-Coder-480B-A35B-Instruct — a 480B-parameter Mixture-of-Experts model with 35B active parameters which supports the context length of 256K tokens natively and 1M tokens with extrapolation methods, offering exceptional performance in both coding and agentic tasks.
Este é outro modelo de pesos abertos licenciados do Apache 2.0, disponível como QWEN3-CODER-480B-A35B-Instruct e QWEN3-CODER-480B-A35B-Instruct-Fp8 no rosto abraçado.
Eu usei a instrução QWEN3-CODER-480B-A35B no playground hiperbólico para executar o meu prompt de teste “Gere um SVG de um pelicano que monta uma bicicleta”:

Na verdade, eu prefiro um pouco o que recebi de QWEN3-235B-A22B-07-25.
Além do novo modelo, a QWEN divulgou sua própria opinião sobre um assistente de codificação de terminal agentico chamado QWEN-Code, que eles descrevem em sua postagem no blog como sendo “bifurcado do Código Gêmeos” (eles querem dizer Gemini-Cli)-que é o Apache 2.0, para que um garfo esteja de acordo com a licença.
Eles se concentraram Muito difícil No desempenho do código para esta versão, incluindo a geração de dados sintéticos testados usando 20.000 ambientes paralelos na Alibaba Cloud:
Na fase pós-treinamento do QWEN3-Coder, introduzimos o longo horizonte RL (agente RL) para incentivar o modelo a resolver tarefas do mundo real por meio de interações com várias turnos usando ferramentas. O principal desafio do agente RL está no escalonamento do ambiente. Para resolver isso, construímos um sistema escalável capaz de executar 20.000 ambientes independentes em paralelo, alavancando a infraestrutura da Alibaba Cloud. A infraestrutura fornece o feedback necessário para o aprendizado de reforço em larga escala e apoia a avaliação em escala. Como resultado, o QWEN3-Coder atinge o desempenho de última geração entre os modelos de código aberto no banco do SWE verificado sem escala no tempo de teste.
Para polir ainda mais suas credenciais de codificação, o anúncio inclui instruções para executar seu novo modelo usando o código Claude e o CLINE usando URLs de base de API personalizados que apontam para os proxies de compatibilidade de Qwen.
Os preços dos modelos hospedados de Qwen (através da Alibaba Cloud) parecem competitivos. Este é o primeiro modelo que eu vi que define preços diferentes para quatro tamanhos diferentes de entrada:
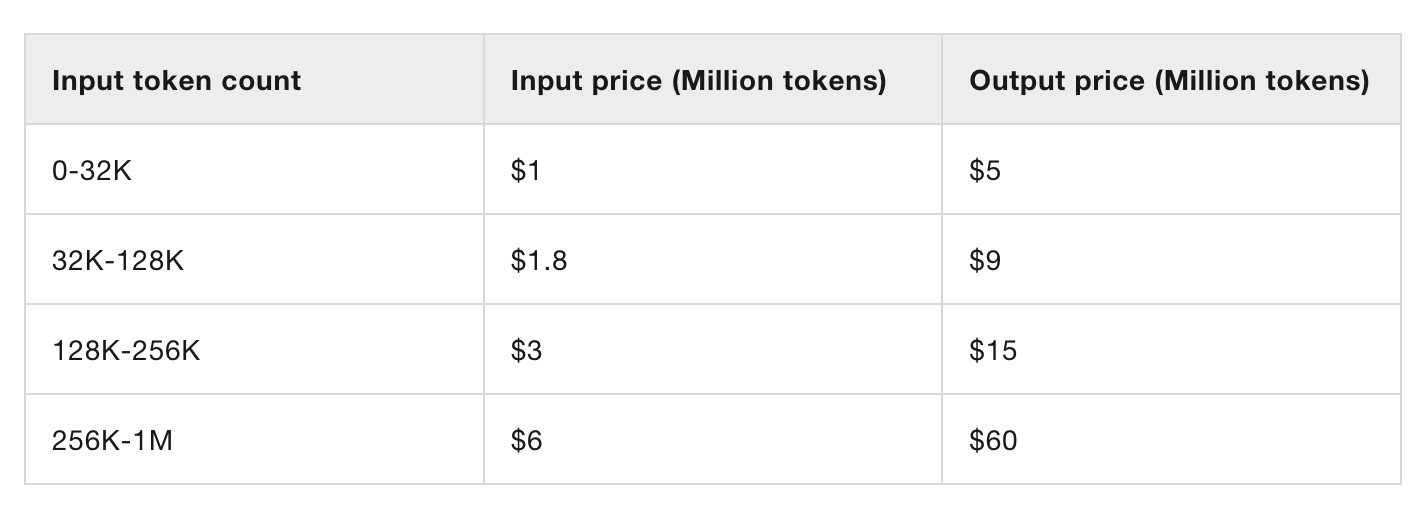
Esse tipo de preço reflete como a inferência contra entradas mais longas é mais caro de processar. O Gemini 2.5 Pro tem dois preços diferentes para mais ou menos de 200,00 tokens.
Awni Hannun relata executando uma versão MLX quantizada de 4 bits em um estúdio Ultra Mac de 512 GB M3 em 24 tokens/segundo usando 272 GB de RAM, obtendo ótimos resultados para “write a python script for a bouncing yellow ball within a square, make sure to handle collision detection properly. make the square slowly rotate. implement it in python. make sure ball stays within the square“.





