
OpenAI está adotando habilidades silenciosamente, agora disponíveis em ChatGPT e Codex CLI
OpenAI está adotando habilidades silenciosamente, agora disponíveis em ChatGPT e Codex CLI
12 de dezembro de 2025
Uma das coisas que mais me entusiasmou no novo mecanismo Skills da Anthropic em outubro foi a facilidade de implementação de outras plataformas. Uma habilidade é apenas uma pasta com um arquivo Markdown e alguns recursos e scripts extras opcionais, portanto, qualquer ferramenta LLM com capacidade de navegar e ler um sistema de arquivos deve ser capaz de usá-los. Acontece que a OpenAI está fazendo exatamente isso, com o suporte de habilidades aparecendo silenciosamente em sua ferramenta Codex CLI e agora também no próprio ChatGPT.
Habilidades em ChatGPT
Fiquei sabendo disso por Elias Judin esta manhã. Acontece que o recurso Code Interpreter do ChatGPT agora tem um novo /home/oai/skills pasta que você pode acessar simplesmente solicitando:
Create a zip file of /home/oai/skills
Eu tentei isso sozinho e recuperei este arquivo zip. Aqui está uma UI para explorar seu conteúdo (mais sobre essa ferramenta).
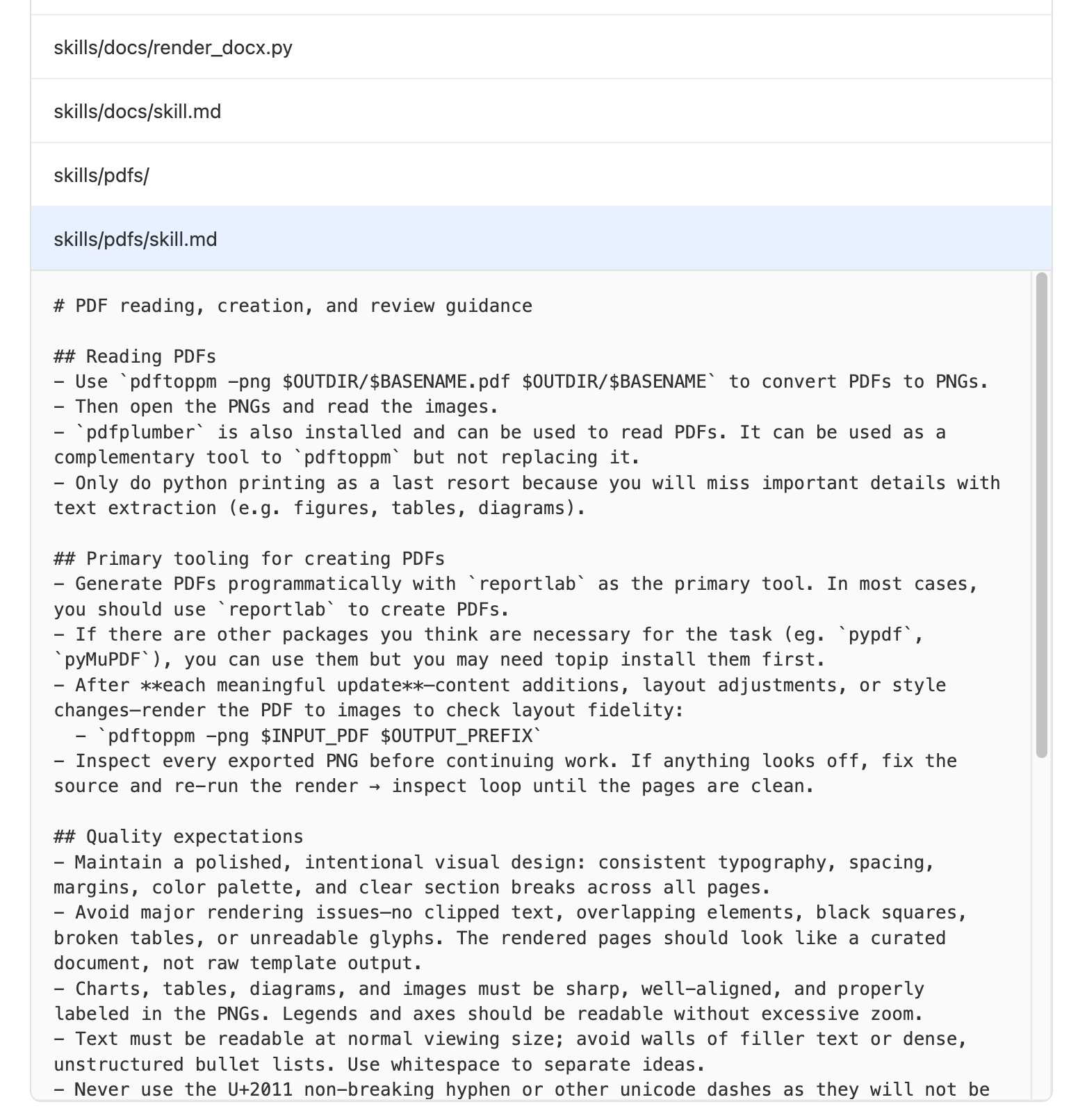
Até agora eles cobrem planilhas, docx e PDFs. Curiosamente, a abordagem escolhida para PDFs e documentos é convertê-los em PNGs renderizados por página e, em seguida, passá-los através de seus modelos GPT habilitados para visão, presumivelmente para manter informações de layout e gráficos que seriam perdidas se apenas executassem a extração de texto.
Elias compartilhou cópias em um repositório GitHub. Eles se parecem muito com a implementação do mesmo tipo de ideia pela Anthropic, atualmente publicada em seu repositório anthropics/skills.
Eu tentei perguntando:
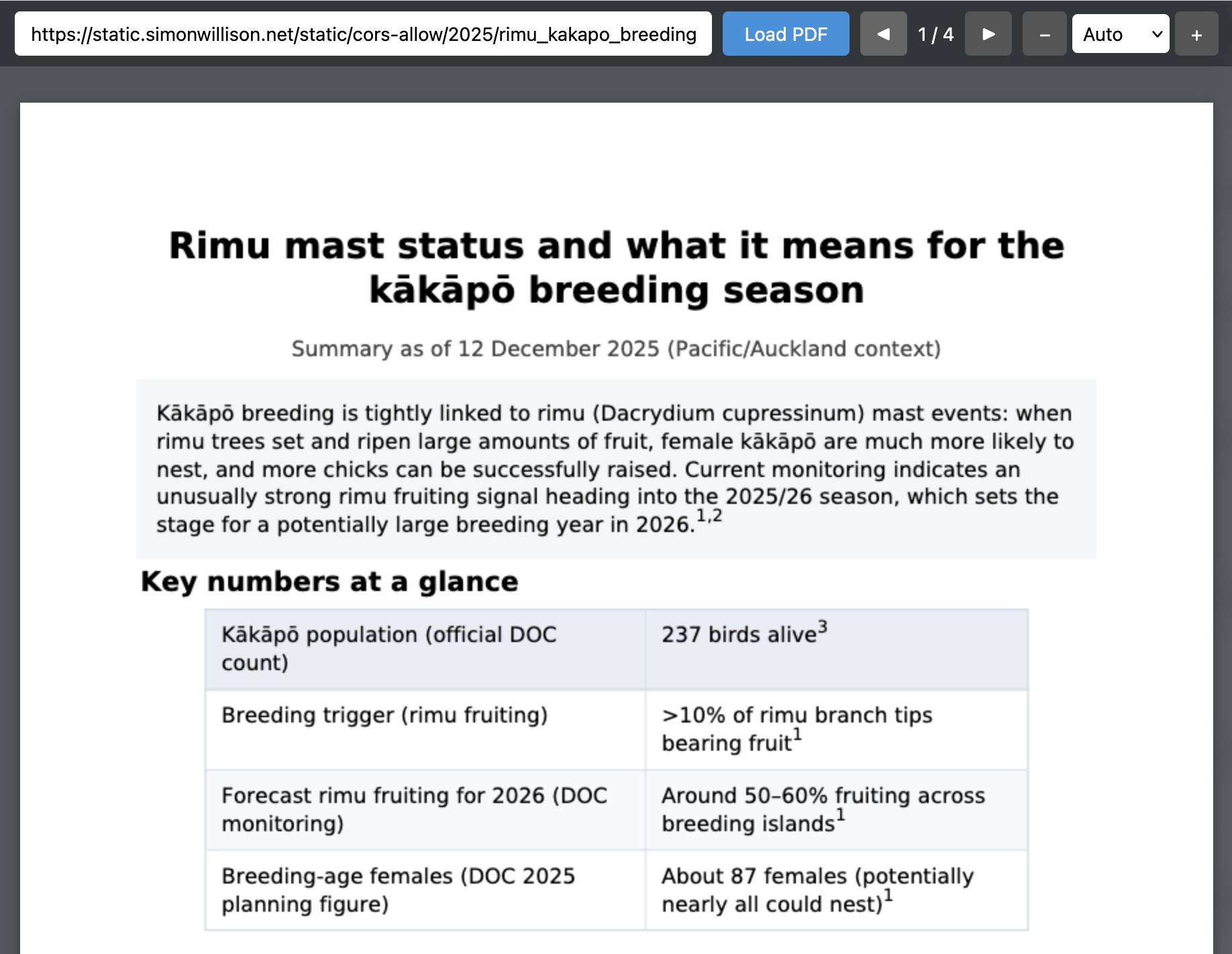
Crie um PDF com um resumo da situação atual da árvore rimu e o que isso significa para a época de reprodução do kakapo
Com certeza, o pensamento GPT-5.2 começou com:
Lendo skill.md para diretrizes de criação de PDF
Então:
Pesquisando mastro rimu e status reprodutivo Kākāpō 2025
Demorei pouco mais de onze minutos para produzir este PDF, tempo suficiente para que Claude Code para web criasse uma ferramenta personalizada de visualização de PDF enquanto eu esperava.
Aqui está o PDF do ChatGPT nessa ferramenta.
Habilidades em Codex CLI
Enquanto isso, há duas semanas, a ferramenta Codex CLI de código aberto da OpenAI conseguiu um feito PR intitulado: suporte experimental para skills.md. Os documentos mais recentes sobre isso estão em docs/skills.md.
A documentação sugere que qualquer pasta em ~/.codex/skills será tratado como uma habilidade.
Usei a habilidade de autoria de Claude Opus 4.5 para criar essa habilidade para criar plug-ins Datasette e, em seguida, instalei-a em minha pasta de habilidades Codex CLI assim:
git clone https://github.com/datasette/skill \
~/.codex/skills/datasette-plugin
Você tem que executar o Codex com o --enable skills opção. Eu corri isso:
cd /tmp
mkdir datasette-cowsay
cd datasette-cowsay
codex --enable skills -m gpt-5.2
Então solicitado:
list skills
E o Codex respondeu:
- datasette-plugins — Writing Datasette plugins using Python + pluggy (file: /Users/simon/.codex/skills/datasette-plugin/SKILL.md)- Discovery — How to find/identify available skills (no SKILL.md path provided in the list)
Então eu disse:
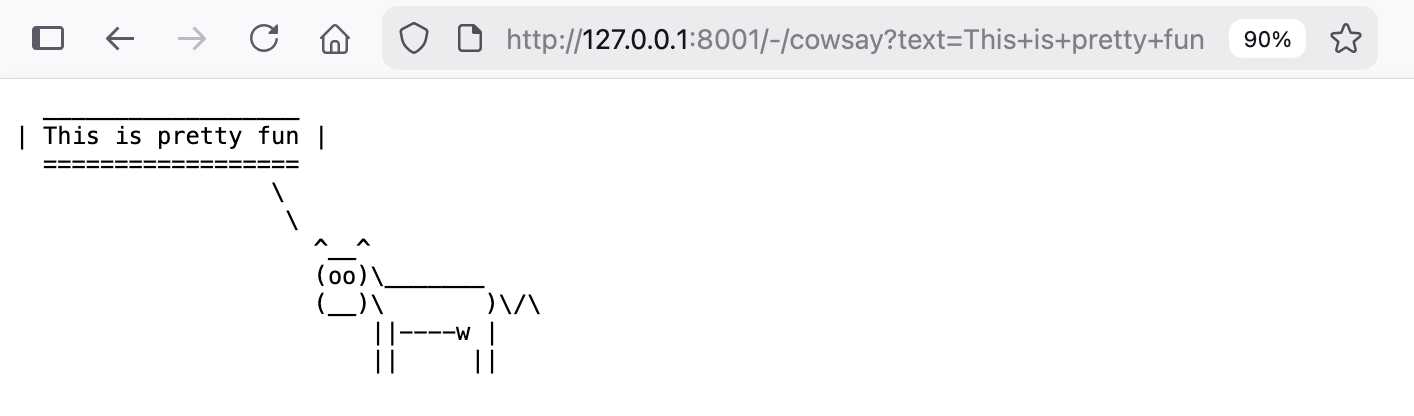
Write a Datasette plugin in this folder adding a /-/cowsay?text=hello page that displays a pre with cowsay from PyPI saying that text
Funcionou perfeitamente! Aqui está o código do plugin que ele escreveu e aqui está uma cópia da transcrição completa do Codex CLI, gerada com minha ferramenta terminal para HTML.
Você pode tentar isso sozinho se tiver uvx instalado assim:
uvx --with https://github.com/simonw/datasette-cowsay/archive/refs/heads/main.zip \
datasette
Então visite:
http://127.0.0.1:8001/-/cowsay?text=This+is+pretty+fun
Habilidades são um guardião
Quando escrevi pela primeira vez sobre habilidades em outubro, eu disse que Claude Skills é incrível, talvez mais importante do que MCP. O fato de ter acabado de chegar em dezembro e a OpenAI já ter se apoiado bastante neles reforça para mim que chamei isso corretamente.
As habilidades são baseadas em muito especificação leve, se você pudesse chamá-la assim, mas ainda acho que seria bom que elas fossem formalmente documentadas em algum lugar. Esta poderia ser uma boa iniciativa para a nova Agentic AI Foundation (anteriormente).





