
Kimi K2 Pensando
Kimi K2 Pensando. O Kimi K2 do laboratório chinês de IA Moonshot se estabeleceu como um dos maiores modelos de peso aberto – 1 trilhão de parâmetros – em julho. Eles agora lançaram a versão Thinking, também com um trilhão de parâmetros (MoE, 32B ativos) e também sob sua licença MIT modificada personalizada (portanto, não exatamente de código aberto).
Começando com Kimi K2, nós o construímos como um agente pensante que raciocina passo a passo enquanto invoca ferramentas dinamicamente. Ele estabelece um novo estado da arte no Último Exame da Humanidade (HLE), BrowseComp e outros benchmarks, aumentando drasticamente a profundidade do raciocínio em várias etapas e mantendo o uso estável da ferramenta em 200 a 300 chamadas sequenciais. Ao mesmo tempo, K2 Thinking é um modelo de quantização INT4 nativo com janela de contexto de 256k, alcançando reduções sem perdas na latência de inferência e no uso de memória da GPU.
Este tem apenas 594 GB no Hugging Face – Kimi K2 tinha 1,03 TB – o que acho que se deve à nova quantização INT4. Isso torna o modelo mais barato e mais rápido de hospedar.
Até agora, as únicas pessoas que o hospedam são os próprios Moonshot. Eu tentei por meio de sua própria API e por meio do proxy OpenRouter, por meio do plugin llm-moonshot (de NickMystic) e meu plugin llm-openrouter respectivamente.
O burburinho em torno deste modelo até agora é muito positivo. Poderia este ser o primeiro modelo de peso aberto competitivo com os mais recentes da OpenAI e Anthropic, especialmente para sequências de chamadas de ferramentas de agente de longa duração?
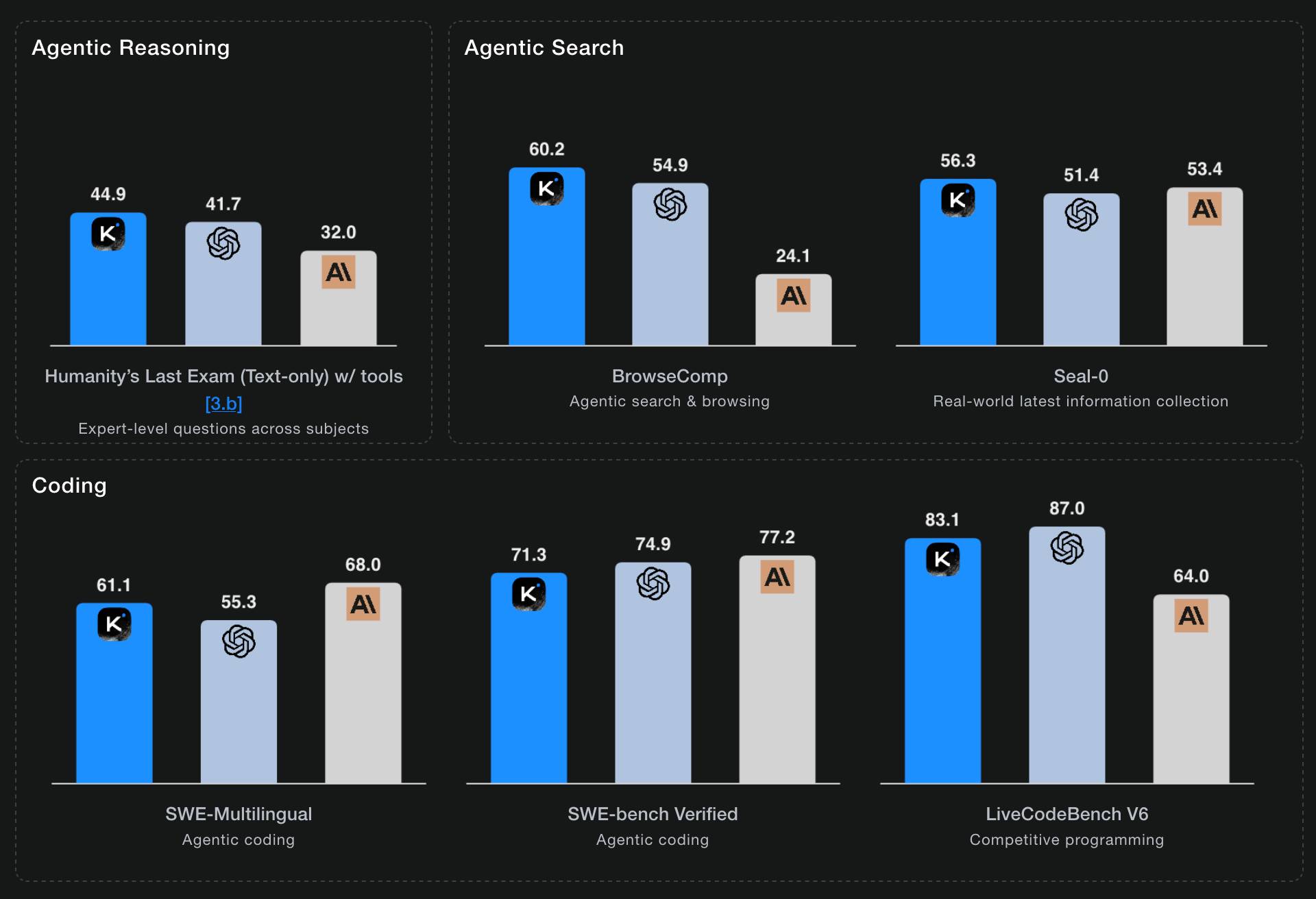
As pontuações de benchmark auto-relatadas da Moonshot AI mostram o K2 Thinking superando os principais modelos OpenAI e Anthropic (GPT-5 e Sonnet 4.5 Thinking) em “Agentic Reasoning” e “Agentic Search”, mas não totalmente no topo em “Coding”:
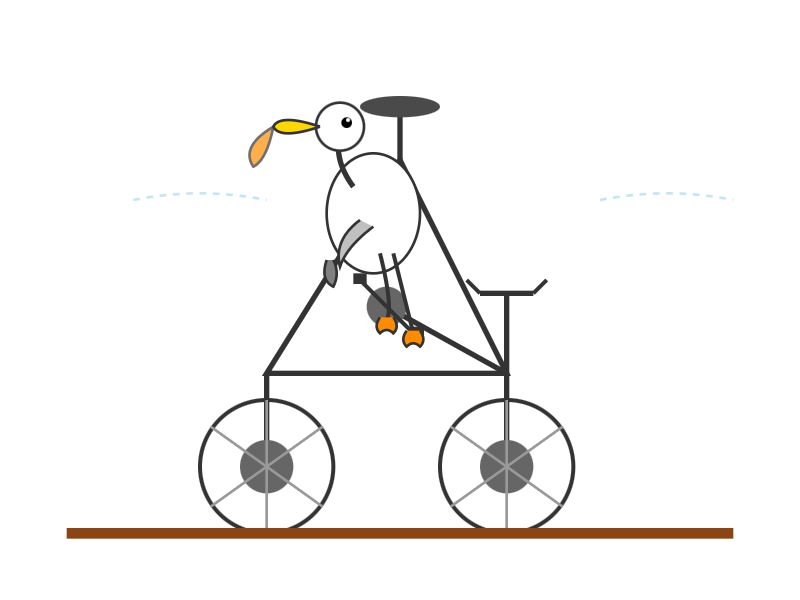
Fiz alguns testes de pelicano:
llm install llm-moonshot
llm keys set moonshot # paste key
llm -m moonshot/kimi-k2-thinking 'Generate an SVG of a pelican riding a bicycle'

llm install llm-openrouter
llm keys set openrouter # paste key
llm -m openrouter/moonshotai/kimi-k2-thinking \
'Generate an SVG of a pelican riding a bicycle'
Análise Artificial disse:
Kimi K2 Thinking atinge 93% no 𝜏²-Bench Telecom, benchmark de uso de ferramenta agentica onde o modelo atua como agente de atendimento ao cliente. Esta é a pontuação mais alta que medimos de forma independente. O uso de ferramentas em contextos de agência de longo horizonte foi um ponto forte do Kimi K2 Instruct e parece que esta nova variante do Thinking traz ganhos substanciais
A CNBC citou uma fonte que forneceu o preço de treinamento do modelo:
O modelo Kimi K2 Thinking custou US$ 4,6 milhões para ser treinado, segundo uma fonte familiarizada com o assunto. (…) A CNBC não conseguiu verificar de forma independente os números do DeepSeek ou do Kimi.
A desenvolvedora do MLX, Awni Hannun, fez com que funcionasse em dois M3 Ultra Mac Studios:
O novo modelo Kimi K2 Thinking com parâmetro de 1 trilhão funciona bem em 2 M3 Ultras em seu formato nativo – sem perda de qualidade!
O modelo foi treinado com reconhecimento de quantização (qat) em int4.
Aqui ele gerou aproximadamente 3.500 tokens a 15 toks/s usando paralelismo de pipeline em mlx-lm
Aqui está o modelo da comunidade mlx de 658 GB.
”")




